Sharing
In the era of FAIR (Findable, Accessible, Interoperable and Reusable) and Open science, datasets should be made available to the public. Whenever possible, discipline-specific repositories (with or without controlled access) should be used in order to increase the FAIRness of your research outputs. If no such repository is available, there are general-purpose repositories.
Learn more about the FAIR principles
Learn more about Open science
Finding a suitable repository type
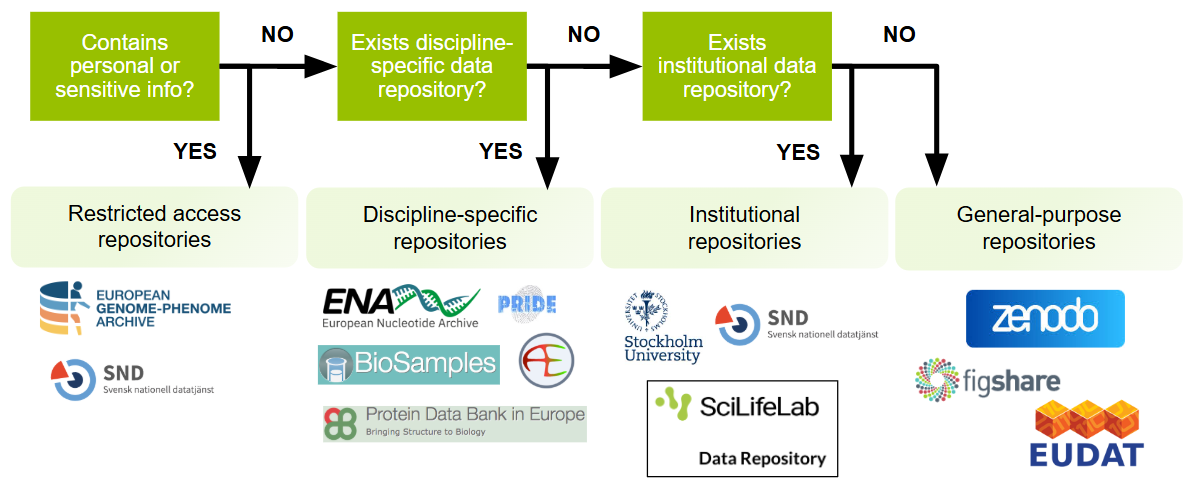
Does your data contain personal or sensitive information that cannot be fully anonymised?
There may be cases where openly sharing data is not feasible due to ethical or confidentiality considerations. Depending on what the ethical board approving your study said about data sharing, and the level of permission granted from participants, it may still be possible to make your data accessible to authenticated users via a controlled-access repository.
See more guidelines on sharing human data
Is there a discipline specific repository for your dataset?
Research data differs greatly across disciplines. Discipline-specific repositories offer specialist domain knowledge and curation expertise for particular data types. Using a discipline-specific repository makes your data visible to others in your community.
Does your institutional repository accept data?
Many institutions offer support to their employees for managing and depositing data. Institutional repositories that accept datasets provide stewardship, helping to ensure that your dataset is preserved and accessible.
Answered no on all questions above?
General-purpose data repositories accept datasets regardless of discipline or institution. These repositories support a wide variety of file types and are particularly useful where a discipline-specific repository does not exist.
Recommended discipline-specific repositories
There are several repositories for life science data types, please find links below to our Data type guide for a selection of the ELIXIR Deposition databases. For other discipline-specific repositories, the EBI repositor wizard can assist in finding the right repository depending on data type, and FAIRsharing.org provides a global registry of repositories.
Guidance on where to publish COVID-19 and Pandemic Preparedness research data, can be found on the Swedish Pathogens Portal.
Cellular and Molecular Imaging
Note that RDMkit provides domain pages with information about data publication and sharing for both Bioimagning data and Proteomics data respectively.
Institutional repositories
For datasets that do not fit into discipline-specific repositories, it is recommended to use an institutional repository if available. These repositories are often general-purpose repositories with the intention of only being used by researchers at that specific institution. See below a selection of available repositories offered by Swedish academic institutions operating in the life sciences.
Visit KI Data Repository
Visit KTH Data Repository
Visit KTH Zenodo community
Visit SciLifeLab Data Repository
Visit Stockholm University Figshare
General-purpose data repositories
A general-purpose data repository is an appropriate choice only if the data does not need to be published in a controlled-access repository, a discipline-specific repository does not exist for the discipline and if there are no institutional repositories available. See below a selection of general-purpose data repositories.
Visit DORIS
Visit Figshare
Visit Zenodo
Visit EUDAT B2SHARE
How can SciLifeLab help you sharing data?
If you are a researcher at a Swedish academic institution operating in the life sciences, you can get help from SciLifeLab Data Management support team. This support team can help you describe and deposit your data. Here are a few examples of the support that is offered:
- Plan data submission
- Identify suitable repositories
- Assist during the submission process when publishing data and code
- Assist in the creation of metadata records in SciLifeLab Data Repository
- Advice on what needs to be done when working with sensitive human data
- Advice on describing data with proper metadata
If you need any help connected to data submission, please contact us by emailing data-management@scilifelab.se.
Resources
Please find below resources concerning the research data life cycle phase share in form of training, guidance and/or tools.
Training resources
Guiding resources
- AIDA Data Sharing Policy
- Data with personal information in DORIS
- EBI submission YouTube playlist
- European Nucleotide Archive (ENA) user documentation
- Guide for submission of metabarcoding data to ENA
- Handbook for data containing personal information
- Keynote: First FAIR steps, Rob Hooft
- National guidelines for open science
- NBIS Submission documentation
- Openscience.se
- RDMkit on Bioimaging data
- RDMkit on Data organisation
- RDMkit on Data publication
- RDMkit on Documentation and metadata
- RDMkit on Proteomics data
- RDMkit on Sharing data
- Research Involving Human Data by Richelle Björvang
- SciLifeLab Data Repository Metadata record tutorial
- SND on Describe, share, and preserve data
Tools
- AIDA Data Hub
- Aspera CLI install instructions
- DORIS
- EBI repository wizard
- ELIXIR Deposition Databases for Biomolecular Data
- EUDAT - B2SHARE
- FAIRsharing
- Figshare
- KI Data Repository
- KTH Data Repository
- protocols.io
- Rclone documentation
- Registry of Research Data Repositories (re3data)
- Researchdata.se
- SciLifeLab Data Repository
- SciLifeLab Protocols
- Stockholm University Figshare
- The Swedish Reference Genome Portal
- Zenodo